身為一個系統管理者,時常要花時間確保系統正常運行,這時一個好的監控系統就很重要,將所有必要的資訊統整在一個畫面上一目瞭然,既能節省時間,當有問題時又能快速找出問題所在,好處多多。
從前從前,在我還小的時候(大概三四年前),我租了一台小的 Ubuntu cloud server 來跑一些小專案,從那時候開始我就一直想要一個可以監控程式或者伺服器的狀態的東西,那時候查到了 pm2 monitor 跟 netdata ,其中 netdata 那時候搞半天弄不好(現在有了 docker 大概一秒就搞定吧),再加上我比較在意我的 node.js 的程式狀態,最後選擇使用 pm2 monitor。
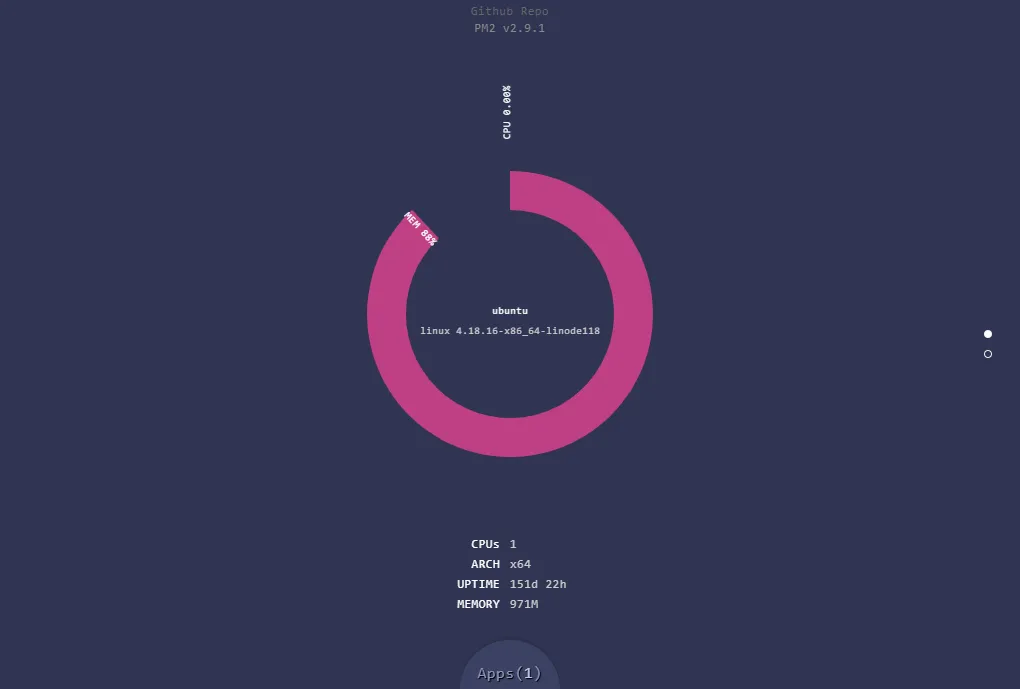 pm2 monitor screenshot
pm2 monitor screenshot過一陣子後,正好有機會成為 CMLab 的網管,一下子要管的機器從原本自己的一台變成超過二十台,又重新讓我思考該怎麼才能好好監控這些機器的狀態。那時候前人(學長姊吧?)留下來的一個網頁,採用 snmp 協定將各台資料彙整至 web server,實作上使用 perl 彙整並產生 HTML 檔,呈現如下:
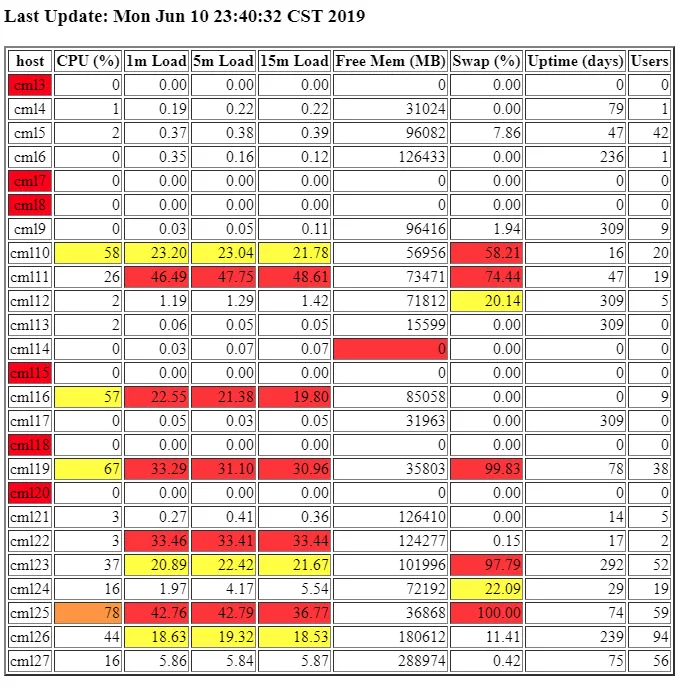
老實說雖然簡陋,但完全可以一目瞭然各台機器狀況,可以稱做一個不錯的監控系統了,那時候我也基於這個網頁再實作額外的自動警報系統,當記憶體或 CPU 用量過高時,發警訊到我的 Facebook Messanger 群組。順便呢也寫了一篇文章記錄: 用 Facebook 聊天機器人當通知系統
從那時候之後我就秉持著要啥自己幹的原則,又利用類似 Pull Based 的方式由一台機器整合的作法,實作出另一套專門監控多台 GPU 伺服器的 Multi-server GPU status monitor,實驗室大家看起來也是挺喜歡這個的 (還曾被教授關注表示讚 🥰),至今仍在運作也令我相當開心~
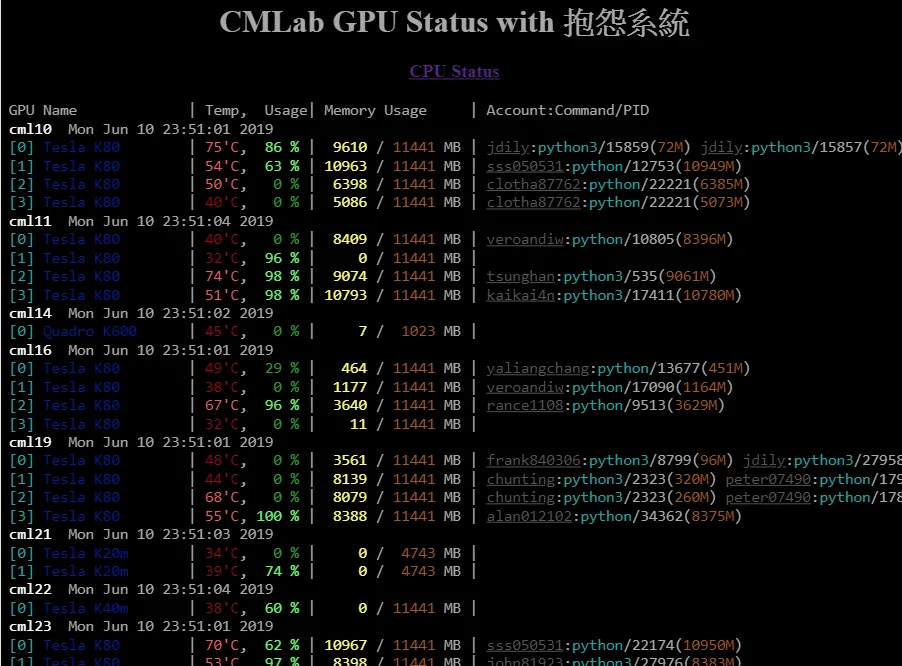 Multi-server GPU status monitor 暨用量檢舉系統一隅
Multi-server GPU status monitor 暨用量檢舉系統一隅時間快轉到近期,又遇到一樣的狀況:同樣有一堆機器要監控。於是我就又再自幹了一套,只是這次實作方式並非是各自產生資料再由一台彙整的作法,而是一台機器主動去各台電腦撈取狀態。當然,這次重作絕對是做得比以前實驗室那用 perl 寫的來的好維護許多,外觀上也比較漂亮~
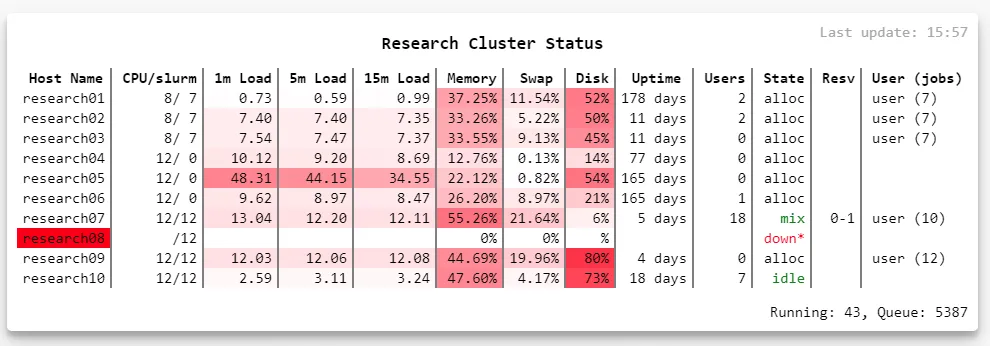 示意圖。任何狀態: 機器死掉、閒置、目前使用狀況都顯示在同一個畫面上。
示意圖。任何狀態: 機器死掉、閒置、目前使用狀況都顯示在同一個畫面上。依舊是要啥自己做、高度客製化,整合所有我想知道的事情,稍微不一樣的是這次我將前後分離,資料搜集器負責蒐集我在意的資料 (metrics),存成 JSON file 直接由前端抓取,資料形式大致如下:
1 | [ |
這樣做的好處是這些 metrics 可以直接被其他人存取,像是我另外用 React Native 來做手機版的 Dashboard;以及一些 Alerter 就是直接讀取這個 JSON,有別於之前寫的 Facebook Messanger Alerter 去爬網頁才得到資料,少繞一圈。
然而就在最近,有同事就說:阿幹嘛不用 Prometheus ? 研究一下才發現,嗯…這東西真的很厲害 XD
有 Prometheus 當 metric collector,加上 Grafana 高度客製化的前端 Dashboard,要監控甚麼幾乎只剩要實作 exporter 而已(而且大部分狀況都有現成的)。
整個心路歷程走過來,從一開始用簡單的現成工具 => 自幹 => 自幹(前後端分離)=> 到最後又回到使用現成但更成熟的工具… 有種繞了一圈的感覺哈哈。
但我還是認真覺得我自己做的 Dashboard 比 Grafana 好看…