隨著實驗室 GPU 資源日益增加,
有越來越多人在抱怨搶不到 GPU、不知道哪台有空的 GPU 、有人佔用太多 GPU 資源等等問題,
這些問題似乎跟沒有一個方法可以「一目瞭然的知道所有 GPU 的狀況」有關。
對,就像是 cml-status 一樣,
假設有個 GPU 版的 cml-status,應該就可以讓大家更輕易地找到閒置的 GPU,如果有人佔用過多運算資源也容易發現。
於是 CMLab GPU Status 就誕生拉~
現況
由於我們有數台伺服器是有 GPU 資源的,所以要做出一個網頁版的監控系統大概要有兩個步驟:
- 彙整各台資訊到某一台 server
- 將這些資訊轉成網頁形式呈現
對於第一點大概有兩種做法,一是主動去取得資訊,也就是透過 ssh 登入到各個有 GPU 的伺服器詢問資訊;二是各個有 GPU 的伺服器各自回報資訊給某一台來彙整。
而主動去取得資訊的方法有幾個缺點,
- 透過 ssh 登入需要密碼,當然可以透過建立 ssh 認證來省去這一步,但好麻煩 _:(´□`」 ∠):_
- 這種方法會使得事情都是一台伺服器在做(又要登入各台又要彙整資訊),感覺不是很人道…
另一個方法則是「各自回報,統一呈現」,
就是大家各自回報 GPU 狀況,
然後由 web server 統一彙整資訊,
這種感覺就比較人道一點,大家一起分擔工作~
各自回報,統一呈現
決定了大方向的做法以後,可以繼續切分整件事情的流程:
- 各台機器如何回報?回報去哪?
- 如何彙整?
- 如何以網頁呈現?
各台機器如何回報、回報去哪?
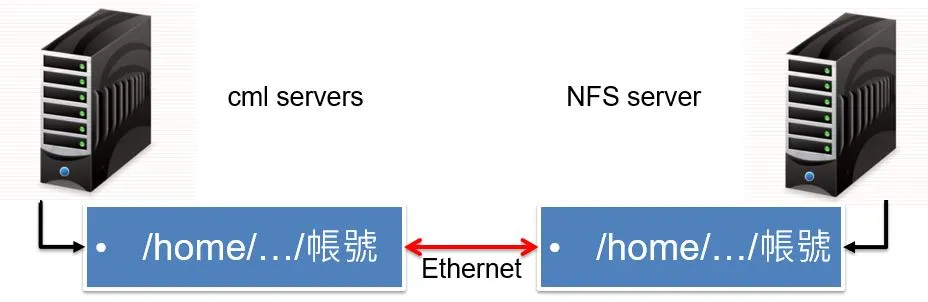 實驗室每台伺服器都有共用一個 NFS
實驗室每台伺服器都有共用一個 NFS幸好我們的 server 都有用 NFS ,所以各自回報到 NFS 上就可以讓其他台存取到資訊了。
那獲得 GPU 資訊的方法不外乎就是下 nvidia-smi 來取得囉,但說真的這指令太豐富了,所以我改用別的神人做的指令 gpustat,輸出就乾淨多了~
 gpustat sample output
gpustat sample output所以每一台 GPU server 要做的是「每分鐘回報一次 GPU status 並存至 NFS」,可以透過 crontab 註冊:
1 | # crontab on each GPU server |
如何彙整?
剛好我們 server 名子都是很沒創意的 cml*,所以彙整相當簡單。
由於各自回報的關係,在 NFS 上會有如下的檔案:
1 | -rw-r--r-- 1 root root 875 Aug 25 23:04 cml10 |
那要彙整就下個 cat cml* 就解決了。
如何以網頁呈現?
最後有了彙整後的資訊後該如何呈現置網頁上呢?
由於我們的 web server 有 apache,所以基本上只要多搞個資料夾底下有 index.html就可以了。
所以只要想辦法將彙整的資訊轉成 html 即可。
網路上大神很多,我又發現了 ansi2html.sh ,這工具可以把 terminal output 轉成 html ,並且連顏色都幫你轉成 css ,太神拉~
所以要變成網頁呈現就可以註冊個 crontab:
1 | # crontab on web server |
每分鐘重新刷新 index.html
BUG
做好以後還是逃不掉 BUG 的摧殘QQ
有時候會發現彙整的資訊會缺少某幾台 GPU server 的資訊
查來查去發現原來是因為 crontab 註冊的時間一樣(都是每分鐘),再加上 NFS 是透過網路傳輸所以會比較慢,導致各自機器每分鐘回報狀況時檔案還沒寫入,web server 就執行彙整動作,就會出現缺檔的情形。
解決方式很簡單,就是彙整時間稍微延遲一點,讓各自回報有時間完成。
1 | # crontab on web server |
用 sleep 即可延遲指令。
雜談
- 差點這個月就要開天窗了…
- 大力募集網管中!