全景照(panorama) 現在已普遍存在手機的相機軟體中,是一種可以拍攝數張照片然後接在一起使整個視野變更大的方法,全景照常比較常見的是往同一方向拍攝的,但也是有上下左右都全景的那種(Photo Sphere)。
以一般往同方向拍攝的一系列照片來說,要合出一張完整的全景照理論上就是將這一系列的照片重疊的部分對齊就可以了。
但實際上還是需要經過一系列的方法,才能接合出比較良好的全景照。
Warp images to cylinder
由於360全景影像的特性,是利用相機旋轉拍攝出環場影像,所以在做偵測特徵點或將照片接起來之前,必須先投影到圓柱體上才會有比較好的效果。
![內圈的黑線分別代表六張照片的成像平面,紅線則是要投影到的圓柱面。<sup>[1]</sup>](/img/2017-05-26/01.jpg.webp) 內圈的黑線分別代表六張照片的成像平面,紅線則是要投影到的圓柱面。[1]
內圈的黑線分別代表六張照片的成像平面,紅線則是要投影到的圓柱面。[1]如同上圖所示,真正拍到的影像是內圈的黑線,分別代表六張照片,但是要接起來必須重新投影到外圈紅色才會接得上。
 右邊的圖木紋的直線都變成有個曲率的彎線。
右邊的圖木紋的直線都變成有個曲率的彎線。這是我將影像投影至圓柱前後的差別,可以看見右邊的圖木紋的直線都變成有個曲率的彎線,這就是投影之後造成的差異。
Feature detection
要找出兩兩照片中的特徵點才好找出照片間的相對位置,所以首先要找出特徵點,這邊我實作的是 Harris corner detector。
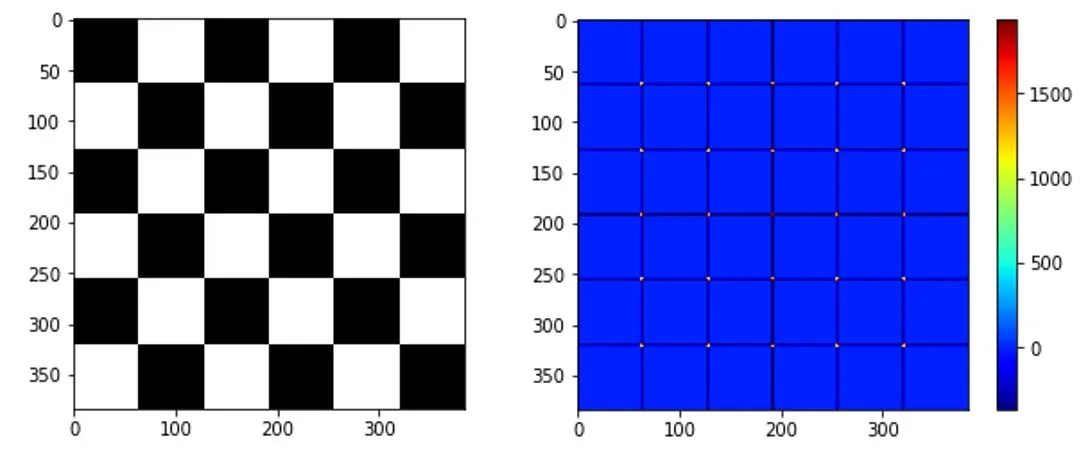 左:用棋盤圖來當作測試資料;右: corner response image
左:用棋盤圖來當作測試資料;右: corner response image這是利用 Harris corner 找出的 corner response image,可以看到交叉點的值都比較高(紅色點),而這些就是應該要挑出來的特徵點。
Feature descriptor
Descriptor 是用來描述特徵點的東西,通常是以高維度的向量來表示,我則是使用 Harris corner 算出 corner response image 之後,將最高的 1% 的點抓出來,以一個 5x5 的 window 來表示成 25 維的向量。
![以周邊像素的值當作 descriptor。<sup>[1]</sup>](/img/2017-05-26/04.jpg.webp) 以周邊像素的值當作 descriptor。[1]
以周邊像素的值當作 descriptor。[1]這是一個 3x3 window 所表示的9維向量,實作上我是使用 5x5。
找出來以後,我還做了一些處理來減少 feature points 的數目:
- 只挑選corner response 最高的 1%
- 切掉上下邊緣(因為投影到圓柱之後會有黑邊)
- 做 local suppression
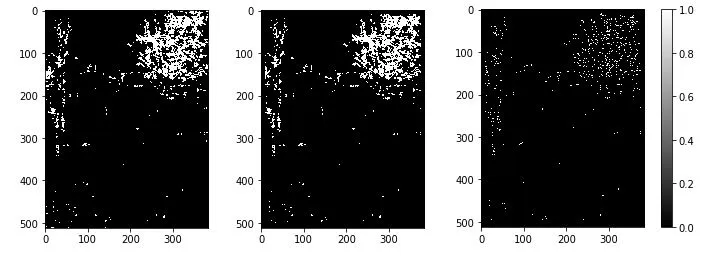 由左至右分別是: 前 1% 的features、切掉上下邊緣、以一個 window size 掃過整張圖,每個 window 中只保留最強的 feature。
由左至右分別是: 前 1% 的features、切掉上下邊緣、以一個 window size 掃過整張圖,每個 window 中只保留最強的 feature。減少 feature 數目最主要的原因是因為希望加快運算速度。
Feature matching
再來就是match出兩兩圖片中對應的點,我用的方法很簡單,就是將兩個影像中找出的 feature descriptors 互相算出向量距離,找出對應的組合。
1 | for i in range(len(descriptor1)): |
以 psudo-code 來表示的話就是兩個 for loop 一個一個算距離找出最小的那組合。是最暴力最直覺的方式 XDDD
其實我也有嘗試對 descriptors 建立 KD-tree 來加速整個 matching 的過程,但是由於 descriptor 是個 25 維的向量,使用 KD-tree 幾乎沒有速度上的優勢,所以最後還是只用這種最單純的算法。
另外,為了達到更好以及更快的 matching 效果,我有定一個假設:「前後兩張影像的垂直差異不會過大」,雖說這假設並不一定成立,但是在 360 環場影像的狀況下還算符合。
 兩張影像中對應的點,以紅色連線來表示。
兩張影像中對應的點,以紅色連線來表示。Find best warp model using RANSAC
再來就是要找出最好的 translation model,進而移動影像來讓兩張影像中相同的部分疊在一起,這邊我用 RANSAC 來找出最佳的 translation model。
RANSAC 基本精神就是隨機挑兩個點的相對位置當作最好的 translation model,然後讓所有 matched pair 都套用這個 model,再來計算有多少個 pair 套用這 model 之後也是有落在可接受的範圍之內。這樣的過程重複跑個幾百次,就有很高的機率可以找出最佳的 translation model。
另外,有時候找出的 matched pair 其實並沒有很多,這時候比起使用隨機選點的方式,直接窮盡所有組合相對快上許多。
Stitch image with Blending
有了兩張圖的相對位置之後就可以來連接兩張影像,但是直接連起來會有很明顯的縫,所以需要做blending。
我實作了兩種blend method:
- Linear blend
- Linear blend with constant width
Linear blend 是最簡單的方式,重疊的部分的顏色由兩張影像加權平均得出,加權的比重如下圖所示,x軸位置接近哪張影像則權重就比較高。
 x軸位置接近哪張影像則權重就比較高
x軸位置接近哪張影像則權重就比較高不過這樣會有一個問題,如果重疊的區域有棵樹在動,那這樣blend就會出現鬼影的問題。
所以我就改成第二種方法,Linear blend with constant width,先找出兩張影像重疊部分的中心線,以此左右取個固定寬度再做 linear blend,這樣就能避免鬼影的問題。
 只在兩張影像重疊部分的中心線左右一點點區間做 linear blend
只在兩張影像重疊部分的中心線左右一點點區間做 linear blend以下是分別用兩種方法所接合的圖,可以看到用第一種方法的左邊的樹明顯糊糊的,右邊的則幾乎沒有鬼影。
 左:第一種方法,可看到樹葉糊糊的;右:第二種方法,沒有鬼影現象。
左:第一種方法,可看到樹葉糊糊的;右:第二種方法,沒有鬼影現象。End to end alignment and Crop
完成所有影像接合之後,會有一些上下的誤差,這時候可以直接將誤差平均分配給每張影像,就可以得出一張比較平的圖片。
原始的接起來的影像,可以看到這一張有嚴重的上下飄移。
 接完以後的原始影像
接完以後的原始影像把誤差平均分配給大家,可以變成比較平的影像。
 經過 end to end alignment 修正之後的圖
經過 end to end alignment 修正之後的圖最後再把上下的黑邊切除掉,就可以得出一張完整的影像。
 裁減掉黑邊的圖。
裁減掉黑邊的圖。Results
這邊展示幾個結果,一張綜覽全貌、一張是原始尺寸(可拖曳)
大雪山登山口。 台大總圖後面。
台大總圖後面。 Testing image from internet
Testing image from internet Testing image from internet
Testing image from internetReferences
- Image from Digital Visual Effects(NTU) slides