敝司長久以來都是自建 Cluster 來做為日常運算資源使用的,長時間一直都被擴充性、I/O 效能所卡住,若是卡在運算資源不夠光是採買新機器動輒要幾個月;被 share storage 的 I/O 效能卡住更慘,整個系統會慢到爆 job 都卡住…
所以我就在想有沒有辦法在雲上建立這種高效能運算叢集,想動態擴張幾台就幾台,再加上我相信無論是 AWS, GCP 等等大平台所提供的 NFS 服務應該都差不到哪裡去吧…?
本文旨在在 Google Cloud Platform 上建立由 Slurm[1] 管理的運算叢集,並且也建立一個 NFS 自動掛載在所有 compute nodes 上面供大家讀取及寫入。
在開始之前要先釐清這個 cluster 需要的東西,基本上是下列:
- A client VM
- Slurm controller
- N nodes of Slurm computing node
- NFS that mount on all computing nodes
整體圖大概長這樣,基本上參考 google 的架構[2],只是加上一個 NFS
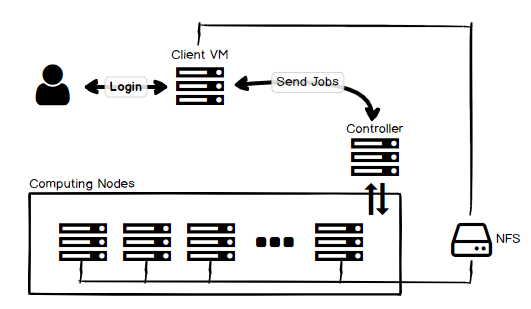 架構圖。Client VM 也需要掛載 NFS
架構圖。Client VM 也需要掛載 NFSCreate a Share Storage
首先先來建立一個儲存空間來當作 NFS ,用於掛載在所有 Nodes 上,這樣才可以在任何地方存取同樣的資料,我這邊選用 Google Filestore 因為他的 I/O 會比一般 Google 的 pd-standard 或 pd-ssd 來的好[3]
建立這個就不太需要介紹了,就跑去 GCP console 案案案就好了,其中一個要注意的是 authorized VPC network 如果沒特別需要,可以選 default 會比較簡單。
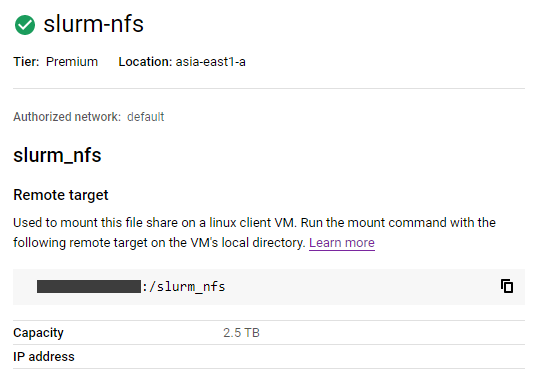 案案案就會得到這個
案案案就會得到這個Setup Slurm Cluster
接下來要來佈屬 Slurm controller, compute nodes, client VM 到 GCP 上,這邊其實已經有整個模板了,github 連結。
這個可以直接用 gcloud 佈署,但在此之前需要先改改 config ,主要要改的是 slurm-cluster.yaml
- cluster_name: 愛取啥取啥
- zone: 既然在台灣就選
asia-east1-b - vpc_net: 這要填
default,不填的話會自動建立{cluster_name}-network的 VPC - vpc_subnet: 填 default 吧
- controller_machine_type: 如果 compute node 打算超過 100 台的話可以選好一點
- network_storage: 這邊要掛載剛剛建立的 nfs
其他就參考以下吧
1 | imports: |
另外一個要改的是 scripts/startup.sh ,這個 script 是 VM 啟動會執行的,由於我們用到 NFS 所以要安裝 nfs package:
1 | # scripts/startup.sh |
我個人認為最大的雷就是 filestore 跟 slurm cluster 必須在同一個 VPC 才能掛載,然後這個 slurm template 不指定 vpc 他會幫你建一個 (不是用 default),所以我一開始搞一直不同 vpc 掛不起來…
Deploy & Test It
設定通通解決後接下來就是佈署上 GCP 了,基本上透過 gcloud 就可以了:
這邊可以 clone 我改過的設定檔 (跟上面說的設定一樣),記得要填 nfs IP
1 | $ git clone https://github.com/SSARCandy/slurm-gcp.git |
接下來要等一下大概五分鐘,因為要建立一個 compute node 的 image,之後要自動擴展 compute node 時使用。
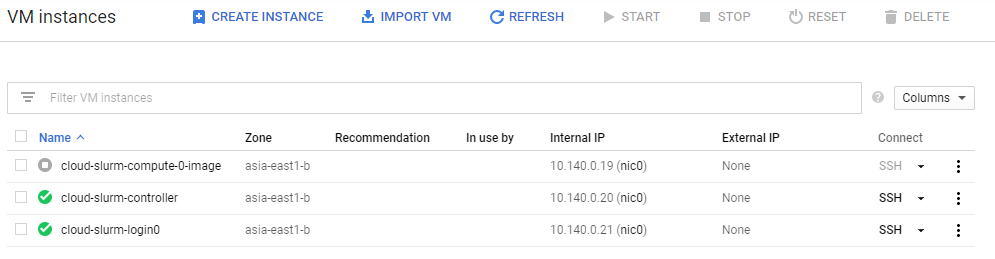 完成後可以在 console 上看到
完成後可以在 console 上看到待一切就序之後就可以登入試試,可以看到 slurm_nfs 也有掛載在上面:
1 | $ gcloud compute ssh cloud-slurm-login0 --zone=asia-east1-b |
利用 sinfo 可以查看 slurm cluster status,有一百台等著被使用。這一百台都是假的,要等到有人真的發 job 才會建立,然後閒置太久就會被關掉,是個很省錢的方式呢~
1 | $ sinfo |
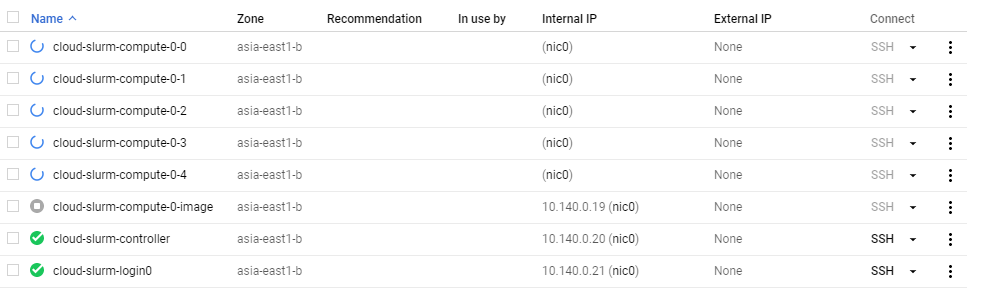 發送 jobs 時才會動態建立 computing nodes,閒置過久會刪掉
發送 jobs 時才會動態建立 computing nodes,閒置過久會刪掉試試看發很多個會寫檔到 NFS 的 job,先建立個 slurm_filewriter.sh,這個檔案會執行寫入 1GB 的資料到 NFS 裡。
1 |
|
然後透過 sbatch 發 jobs,關於 slurm 用法可參考這個小抄
1 | # send 5 parallel jobs that write file to NFS |
至此整個 slurm cluster 就佈署到 GCP 上了,可以開始開心使用啦~
這樣的優點包含可以無上限擴充運算資源,再也不用等待!
NFS I/O 根據我的測試也是完勝自架的分散式儲存系統!
壞處則是可能也許會有些貴…(?)
References
- https://slurm.schedmd.com/documentation.html
- https://codelabs.developers.google.com/codelabs/hpc-slurm-on-gcp
- https://cloud.google.com/compute/docs/disks
雜談
噫!好了!我畢業了!